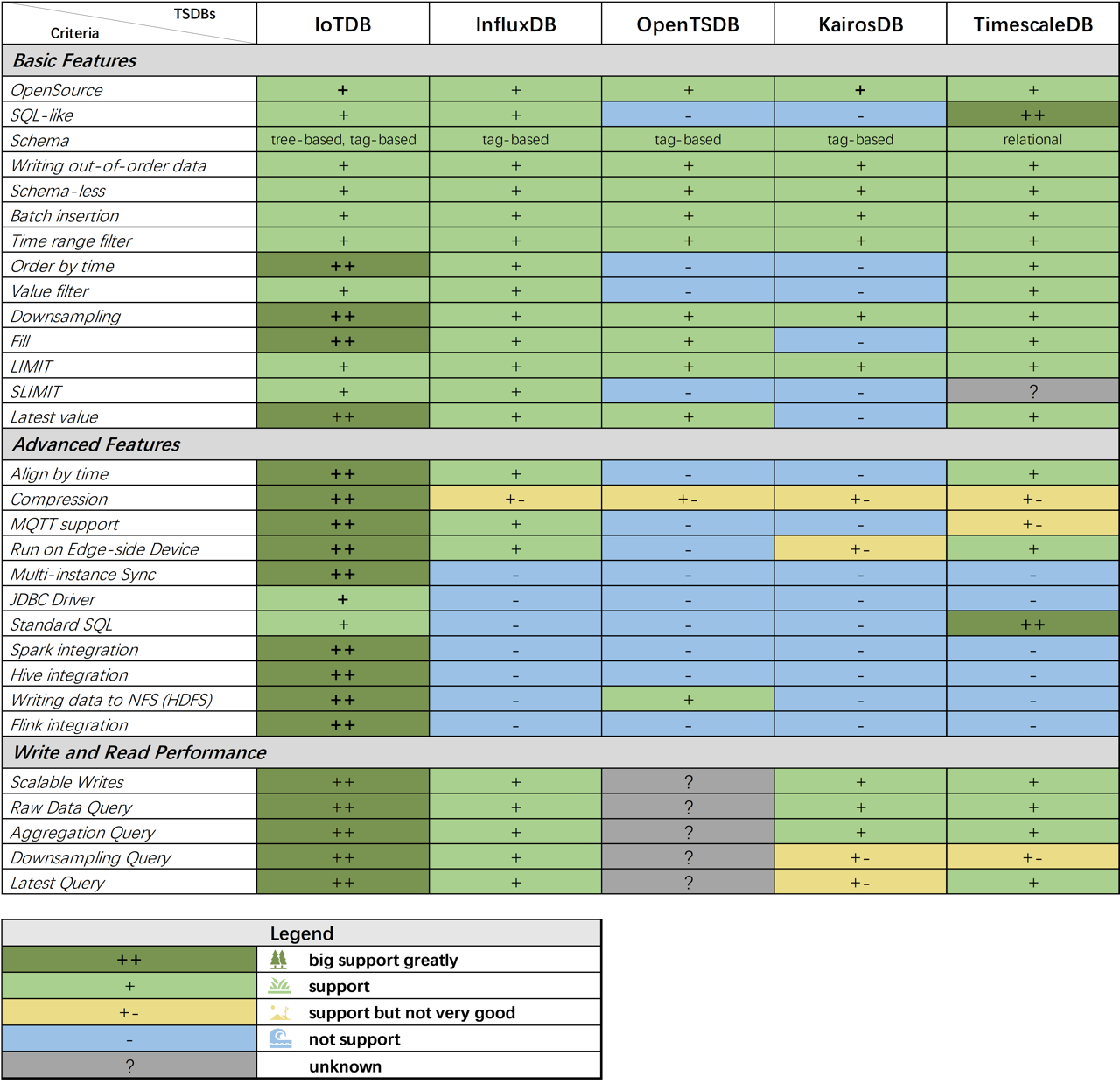
Time-series data is everywhere—from monitoring server performance to tracking IoT device metrics, financial market analysis, and user activity on web applications. Handling this type of data efficiently requires specialized databases that can manage high write volumes, complex queries, and large-scale storage. TimescaleDB has emerged as a leading solution for time-series applications, offering an architecture that blends the reliability of relational databases with the performance of purpose-built time-series systems. In this article, we explore the TimescaleDB TSDB architecture and how it enables building efficient time-series applications.
Understanding TimescaleDB and Time-Series Data
Time-series data refers to data points indexed by timestamps, where the sequence and time intervals are critical for analysis. Unlike traditional relational databases that optimize for general-purpose workloads, time-series databases (TSDBs) are optimized for handling high-frequency inserts, efficient storage, and rapid aggregation of time-stamped data.
TimescaleDB stands out because it extends PostgreSQL, a popular relational database, into a time-series database without requiring developers to learn a new query language. It combines the reliability, security, and ecosystem of PostgreSQL with features specifically designed for time-series workloads. This makes it an ideal choice for developers building applications where time-based insights are essential.
Core Principles of TimescaleDB TSDB Architecture
The TimescaleDB TSDB architecture is designed to optimize performance for time-series workloads while maintaining flexibility. Its architecture relies on three core principles: hypertables, chunking, and compression.
Hypertables: Scaling Beyond Traditional Tables
At the heart of TimescaleDB’s architecture is the concept of hypertables. A hypertable is a virtual table that abstracts a set of underlying tables called chunks. While it appears to the user as a single continuous table, a hypertable automatically partitions data across time intervals (and optionally by space, such as device ID or location). This partitioning is key to efficiently managing massive datasets because it ensures that queries only scan relevant chunks rather than the entire table.
For example, in a monitoring application for IoT devices, a hypertable can store millions of sensor readings per second. Queries targeting a specific time range will only access the corresponding chunks, drastically reducing query latency and improving overall system performance.
Chunking: Managing Large Datasets Efficiently
TimescaleDB divides hypertables into smaller pieces called chunks. Each chunk represents a specific time interval and can be stored separately on disk. This structure allows for efficient data management strategies such as indexing, compression, and retention policies.
Chunking also enables horizontal scalability. In high-throughput scenarios, different chunks can be distributed across multiple disks or nodes, reducing I/O bottlenecks. Developers can define chunk sizes based on the volume of incoming data and query patterns, making TimescaleDB highly adaptable for diverse time-series workloads.
Compression: Reducing Storage Footprint
Storing time-series data at high resolution can consume significant disk space. TimescaleDB addresses this challenge with native compression support. Once data becomes less frequently accessed, it can be compressed using advanced algorithms without sacrificing query performance. Compressed chunks retain full queryability, allowing developers to aggregate or filter historical data efficiently.
This approach is particularly valuable for applications like financial market analytics, where both high-resolution recent data and long-term historical data need to coexist in the same system.
Optimized Query Execution for Time-Series Workloads
Beyond storage optimization, the TimescaleDB TSDB architecture focuses on improving query execution for time-series analytics. Traditional relational databases may struggle with complex time-based queries, such as computing moving averages, identifying trends, or performing downsampling. TimescaleDB provides built-in functions and optimizations tailored to these use cases.
For instance, continuous aggregates allow developers to precompute frequently used queries on time-series data. This reduces computational overhead for dashboards and reporting tools. Additionally, TimescaleDB supports time-bucketed aggregations that simplify operations like summarizing data over minutes, hours, or days.
By leveraging these features, developers building applications with Timecho can ensure that real-time monitoring dashboards and analytical reports remain responsive, even under heavy data loads.
Integration with Existing PostgreSQL Ecosystem
One of the strongest advantages of TimescaleDB is its full integration with PostgreSQL. Developers can use standard SQL for queries, indexes, and joins while benefiting from the specialized features of a time-series database. This lowers the learning curve and enables seamless integration with existing tools and applications.
The PostgreSQL ecosystem also provides robust features like replication, backup, and security. TimescaleDB inherits these capabilities, allowing organizations to deploy reliable, production-grade time-series applications without sacrificing data integrity or compliance.
Use Cases for TimescaleDB in Timecho Applications
Timecho leverages TimescaleDB for applications requiring high-performance time-series analytics. Some notable use cases include:
- IoT Monitoring: Collecting sensor data from thousands of devices per second while enabling real-time alerts and historical trend analysis.
- Application Performance Monitoring (APM): Tracking metrics like CPU usage, memory consumption, and request latency to ensure optimal application performance.
- Financial Analytics: Processing market data streams to identify trading patterns, compute moving averages, and perform backtesting.
- User Behavior Analytics: Storing user interactions to optimize product features, measure engagement, and forecast demand.
In each scenario, TimescaleDB’s architecture ensures that applications remain performant, scalable, and easy to maintain, even as the volume of time-series data grows exponentially.
Designing Efficient Time-Series Applications with TimescaleDB
When building applications on TimescaleDB, it is important to consider architectural best practices:
- Plan for Hypertable Partitioning: Choose appropriate time intervals and optional space dimensions to optimize query performance.
- Leverage Continuous Aggregates: Precompute commonly used metrics to reduce query latency.
- Implement Compression and Retention Policies: Reduce storage costs while keeping historical data accessible.
- Monitor and Tune Indexes: Use indexes strategically on time and space dimensions for faster retrieval.
- Integrate with Visualization Tools: Tools like Grafana and Timecho dashboards work seamlessly with TimescaleDB for real-time data visualization.
By following these principles, developers can create time-series applications that are not only scalable but also maintainable and cost-efficient.
Future of Time-Series Applications with TimescaleDB
As organizations generate ever-increasing volumes of time-stamped data, the demand for efficient time-series solutions will continue to grow. TimescaleDB’s hybrid relational and time-series approach positions it as a foundational component for modern analytics platforms. With features like hypertables, chunking, compression, and PostgreSQL compatibility, TimescaleDB provides a robust, flexible foundation for applications requiring real-time insights and historical analysis.
For developers and businesses using Timecho, adopting TimescaleDB ensures that their applications can scale seamlessly, handle complex queries, and deliver meaningful insights without the overhead of managing a separate time-series system.
Conclusion
The TimescaleDB TSDB architecture provides an innovative solution for efficiently managing and analyzing time-series data. Its hypertables, chunking strategy, and compression capabilities enable applications to handle high write volumes and complex queries while remaining scalable and reliable. By combining the power of PostgreSQL with time-series optimizations, TimescaleDB allows developers to build high-performance applications with lower operational complexity.
For Timecho applications, leveraging TimescaleDB ensures the ability to process massive amounts of time-stamped data, deliver real-time analytics, and maintain historical insights—all critical factors for modern time-series workloads. By understanding and implementing the principles of this architecture, developers can build time-series applications that are both efficient and future-proof.